HerokuにLINE Webhookをデプロイするまで
今回は無料で使えるホスティングサービスであるHerokuにLINE Webhookをデプロイするまでの手順を備忘録的に記します。
作りたいもの
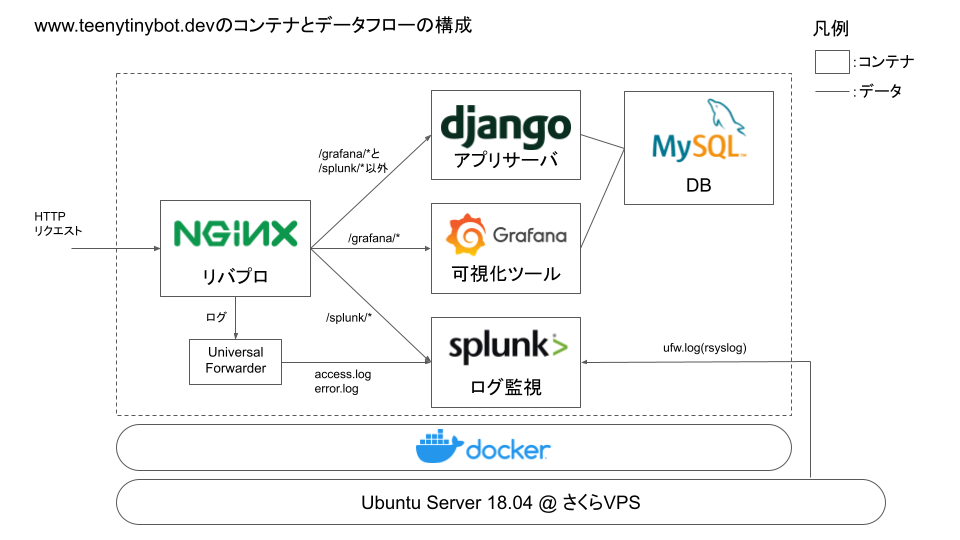
実家でデジタル難民と化している祖母が他の家族からのLINEメッセージを見れるように、↓のようなシステムを作ろうと思い立ちました。
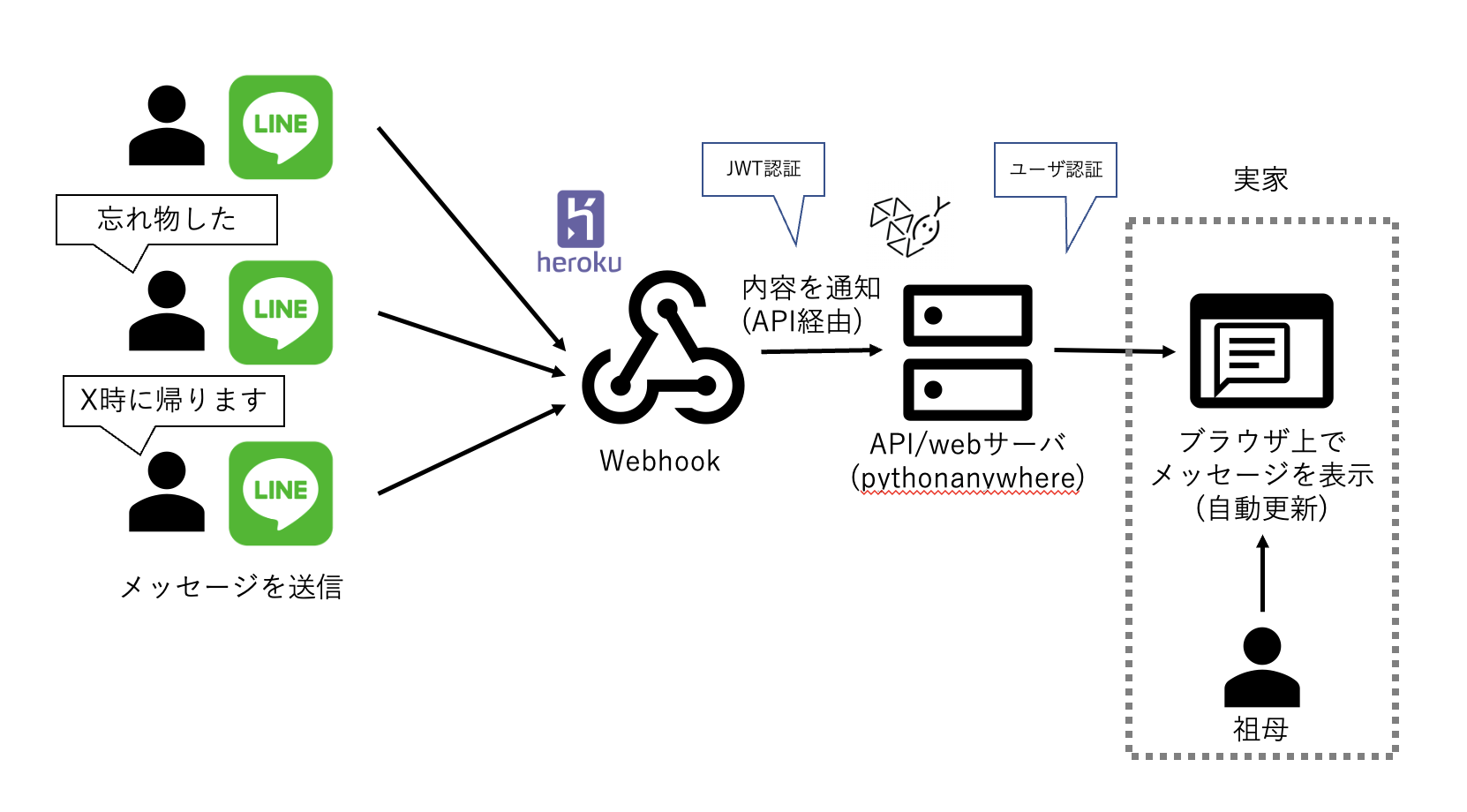
このシステムを作るにあたり、LINEメッセージを送ると自作のAPIにデータをPOSTするようなWebhookをつくりたいです。
今回はゴールとして、まずはLINE bot(Python)に送ったメッセージをそのままLINEで返信してくるようなエコーボットをデプロイすることにします。
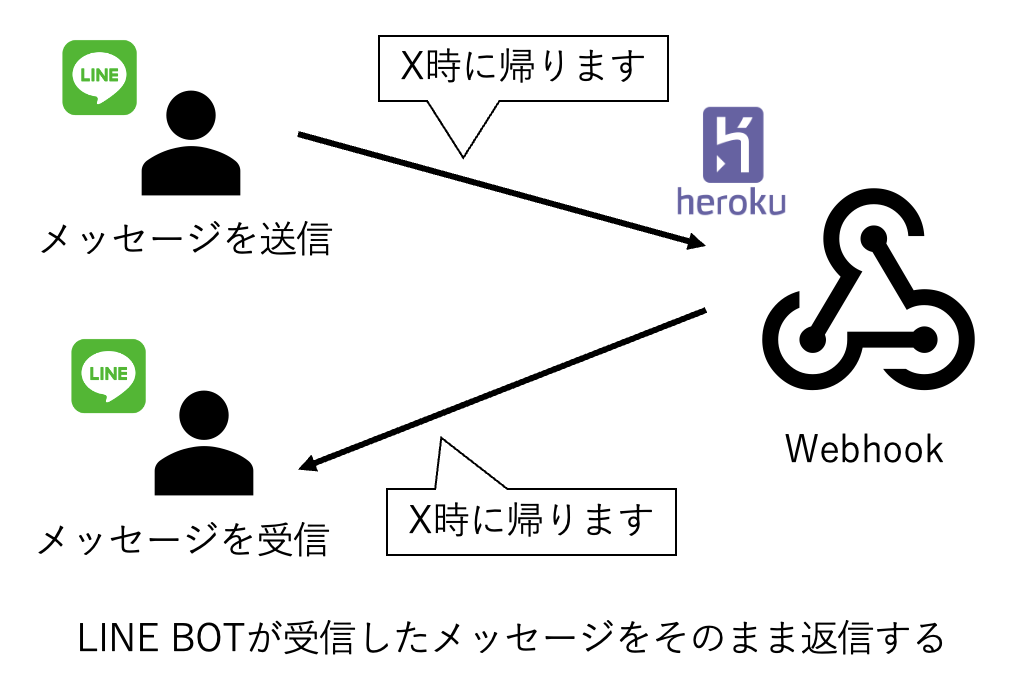
本記事の構成
- 前提(heroku/line developerのアカウント作成等)
- Webhookの構成
- line-bot-sdkについて
- herokuへのデプロイ手順
1. 前提
1.1. herokuのアカウント作成
herokuの利用にはアカウント作成が必要です。今回は無料枠の範疇のことしかしないので、Freeアカウントで作成します。
こちらからアカウントを作成することができます。
また、heroku CLIを使うためインストールが必要です。こちらの手順に従い、インストールしてください。
1.2. LINE Developerアカウントの作成
今回のwebhook作成に関しては、LINEbotが必要となります。LINEbotの作成にはLINE developerアカウントが必要となるため、アカウント登録をおこないます。
こちらからアカウント作成をしてください。
2. webhookの構成
今回のwebhookを作成するにあたり、ローカル上で下記のようなフォルダ構成を作成します。
*/
|__main.py # webhookの処理を記述する
|__requirements.txt # 使用するライブラリの一覧
|__runtime.txt # herokuで使用する言語の諸元
|__Procfile # herokuで実行するコマンド
|__.env # herokuで使用する環境変数
2.1. main.py
main.pyにはline-bot-sdkを使って行う処理を記述することになります。
詳細は3節で説明するため、ここでは説明を省きます。
2.2. requirements.txt
requirements.txtには今回使用するライブラリを記述します。これをプロジェクトフォルダに含めることで、デプロイ時に自動でライブラリをインストールしてくれます。
Flask==2.0.3
line-bot-sdk==2.2.1
requests==2.27.1
2.3. runtime.txt
runtime.txtにはherokuで使用するPythonのバージョンを記述します。その際、herokuが対応しているバージョンを選択しなければならないため、現在のherokuが何に対応しているかを確認するようにします。
今回は以下の内容を記述します。一行のみです。
python-3.9.0
2.4. Procfile
Procfileはheroku上でデプロイ時に実行するコマンドを記述します。今回はmain.pyを実行することでサーバーを立ち上げたいので、下記の内容とします。
web: python3 main.py
2.5. .env
.envファイルはherokuの環境に登録したい環境変数を記述します。main.pyなどに直接記載したくない情報(例えばline-bot-sdkのシークレットキーなど)を記述し、herokuの環境に反映します。
3. line-bot-sdkについて
今回は開発者公式が公開しているline-bot-sdkのサンプルプログラムを使用します。サイトはこちら(GitHub)から見れます。
元のサンプルプログラムはアクセストークンとシークレットキーをベタ書きしているため、この二つだけは環境変数から読み込むように変更を加えています。
from flask import Flask, request, abort
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, TextMessage, TextSendMessage
import os
# Flaskでwebhookを立ち上げ
app = Flask(__name__)
# アクセストークンとシークレットキーは環境変数から読み込む
YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"]
YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"]
line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(YOUR_CHANNEL_SECRET)
@app.route("/callback", methods=['POST'])
def callback():
signature = request.headers['X-Line-Signature']
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
try:
handler.handle(body, signature)
except InvalidSignatureError:
print("invalid signatrue. please check channel info")
abort(400)
return 'OK'
@handler.add(MessageEvent, message=TextMessage)
def handle_message(event):
line_bot_api.reply_message(event.reply_token, TextSendMessage(text=event.message.text))
if __name__ == "__main__":
port = int(os.getenv("PORT"))
app.run(host="0.0.0.0", port=port)
4. herokuへのデプロイに関して
ここまでのプログラムの準備ができたところで、herokuへのデプロイを行います。大まかな手順は下記の通りです。
- heroku上でのプロジェクト作成
- gitリポジトリの作成・登録
- heroku環境変数の反映
- herokuへのpush
4.1. heroku上でのプロジェクト作成
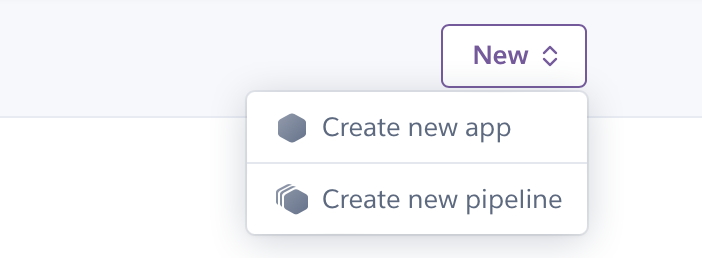
まずは、herokuの個人コンソールから「create new app」を選択し、新しいアプリケーションを作成します。
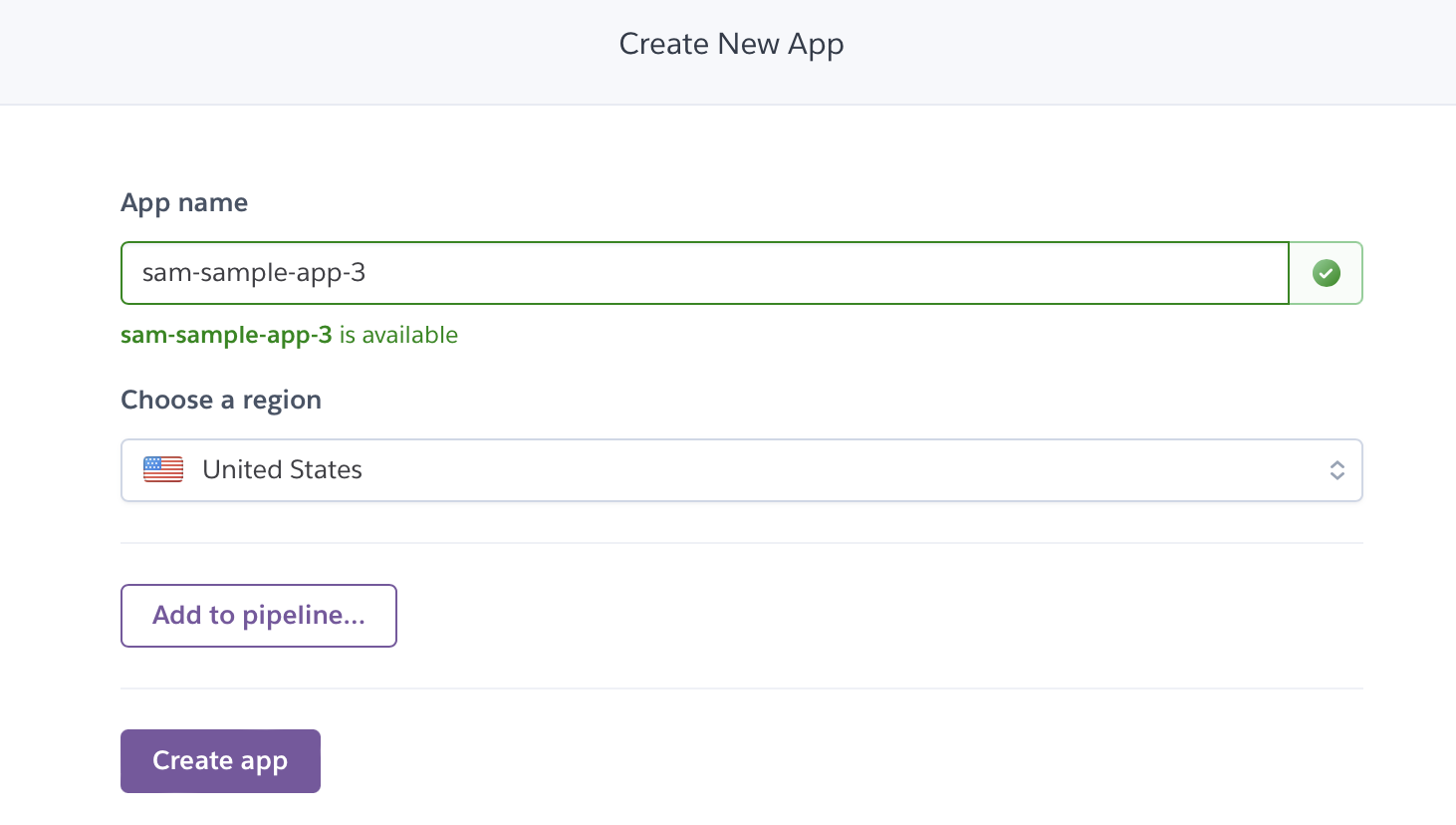
名前を選ぶように促されるので、適当な名前をつけます。「hogehoge.herokuapp.com」というURLを与えられますが、世界で一意な名前である必要があるため、適度に長い名前にしてください。
4.2. gitリポジトリの作成・登録
ローカルのプロジェクトをgitリポジトリとして登録し、herokuにpushします。
ローカルで
git init
git add *
git commit -m "first commit"
とし、まずはgitのローカルリポジトリを作成します。
次に、herokuのリモートリポを紐付けます。heroku CLIから以下を実行します。
heroku git:remote -a {自分のアプリの名前}
このままgit pushすると、環境変数を設定しないままビルドが始まってしまうので、git pushする前に.envファイルで設定した環境変数をherokuに反映します。
4.3. 環境変数の反映
heroku CLIを用いて、.envファイル内に記述した環境変数をherokuのアプリに反映します。
プロジェクトディレクトリ内でheroku config:pushを実施します。成功すると「Successfully wrote settings to Heroku!」とログが出ます。
venv) hogehoge:~/Desktop/line-webhook-app$ heroku config:push
Successfully wrote settings to Heroku!
4.4. herokuへのpush
ここまで実施できたら、git push heroku masterでheroku上のリモートリポジトリにプロジェクトをpushします。
pushが成功すると自動でビルド→デプロイが行われます。
LINE botにメッセージを送って、全く同じ内容の返事が来れば成功です。

プロジェクト内でheroku logs --tailとすると、デプロイしたアプリのログを確認することができます。
うまくLINE botが返事を返してくれなければ、このログを見てトラブルシュートを行います。
まとめ
これまでVPSをメインで使っていたので、herokuのようなPaaSを使えば無料で簡単にデプロイできるんだなと感心しました。